
Intro / hypotesis
The hypotesis here is actually very simple: To use synthetic data to use on a pre-trained AI model, to reckognize body / hand signals.
Divers use a set hand gestures and signals to communicate under water. One specific set of these hand gestures is when they spot marine animals.

Unreal Engine / Blender.
I have borrowed the dummy character from Unreal Engine Third Person template for this experiment.

And I’v gently placed it in Blender, where I stripped it from all major features (color, normals, material attributes)
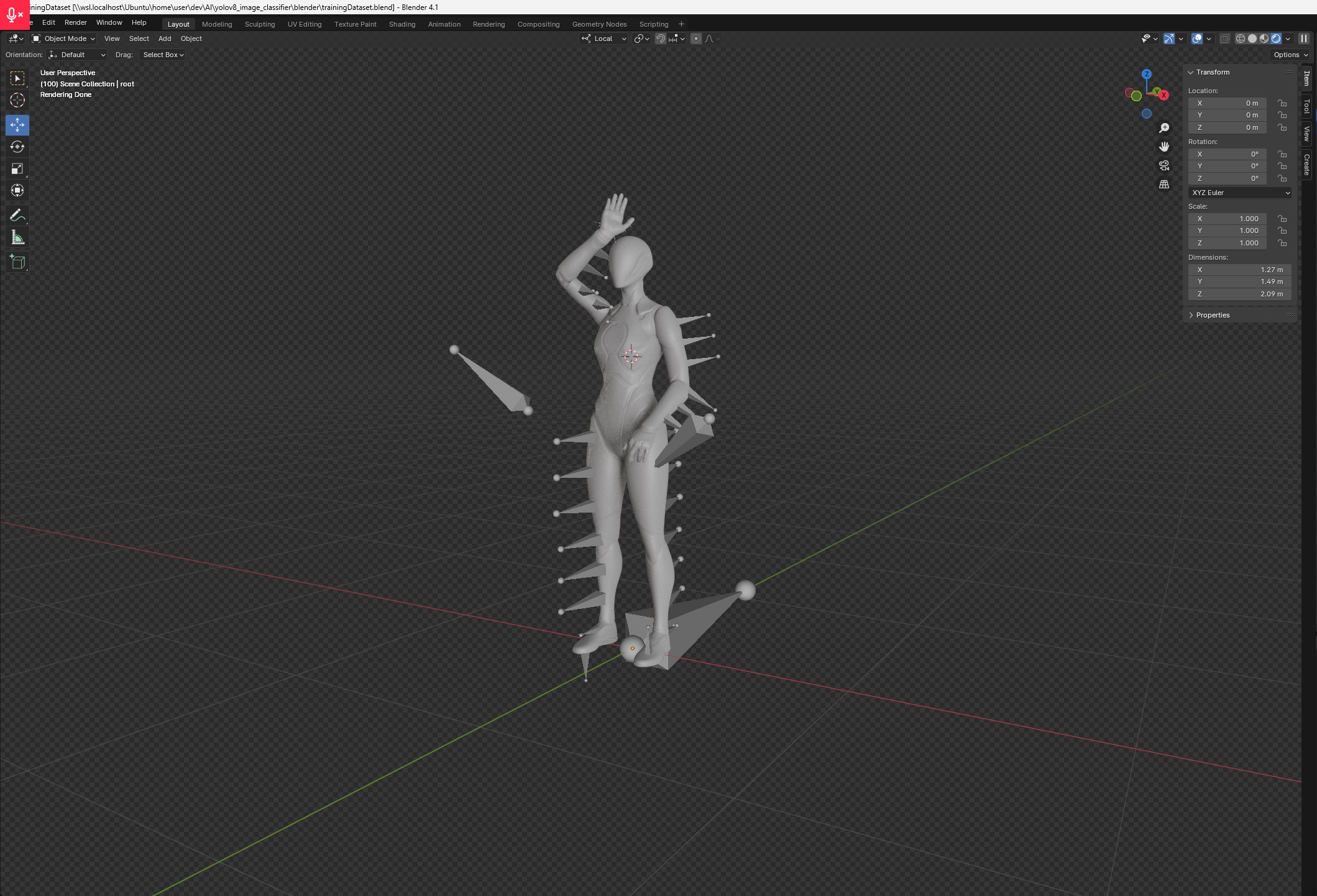
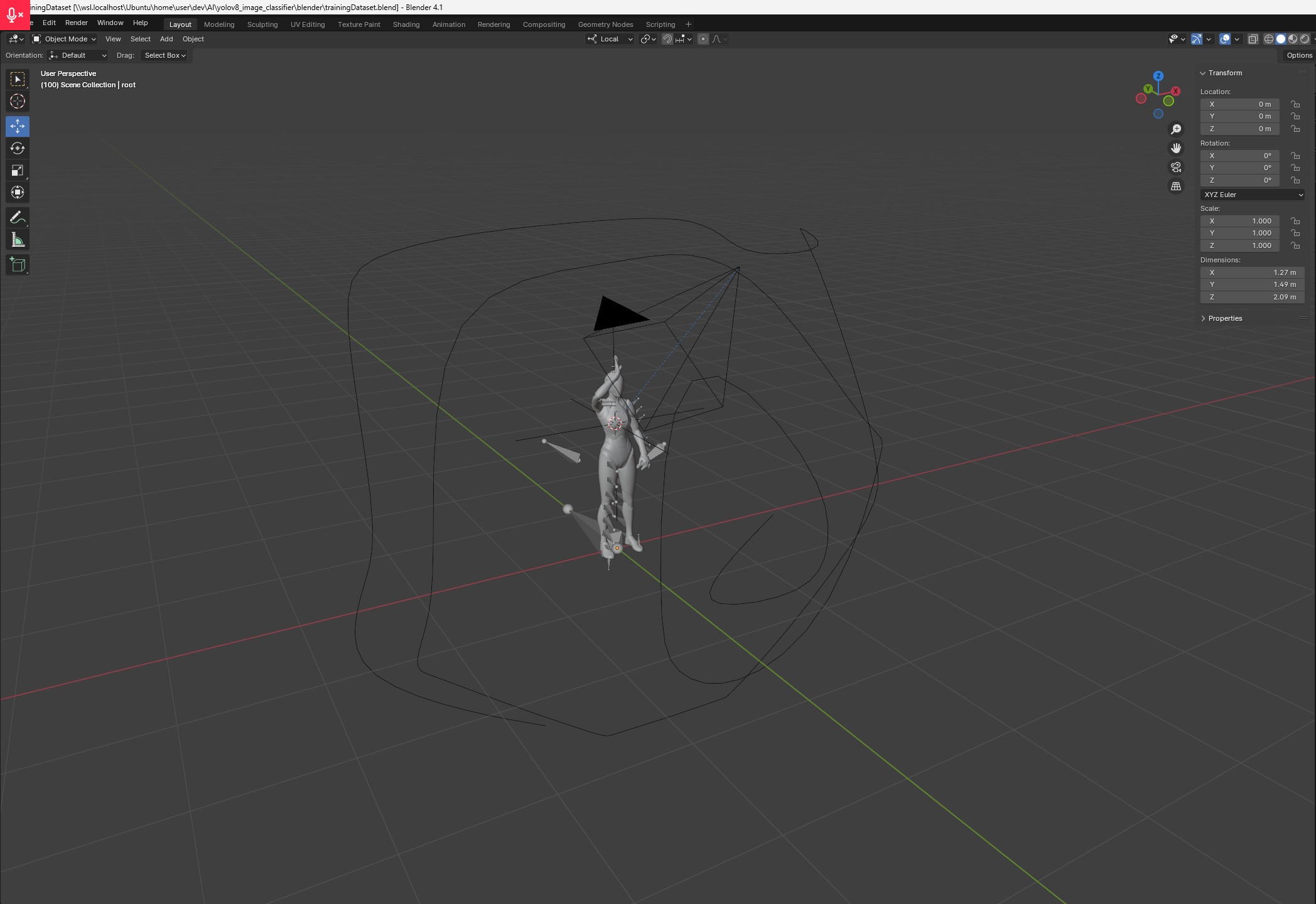
Producing the dataset
I have posed the character in such a way to mimic hand gestures and then produced 250 rendered images, with neutral lighting. The black line is the path the camera does over 250 frames. The camera aim is always pointed at the chest of the character. This allowed to capture the hand gesture from several different angles.
Training the model
I mostly enjoy doing these sort of things on my laptop. But this time given the python requirements, I decided some *CUDA cores woudn’t hurt. So I used my workstation, which mounts an NVidia 4090. For this, I used a neat little hidden feature in Windows, which is called WSL and stands for Windows Subsystem Linux. It’s a pre-packaged ubuntu distro, running on top of windows with access to CUDA.
The pre-trained model of choice this time was yolov8n-cls.pt. Yolov8 requires a pre-determined folder structure for training, which is actually very simple:
- Dataset_dir/
- train/
- val/
Load & Train model
from ultralytics import YOLO
# load a pretrained model
model = YOLO('yolov8n-cls.pt')
# train model on syntetic dataset
model.train(data='/home/user/dev/AI/yolov8_image_classifier/data/marineanimals',
epochs=10,
imgsz=64)
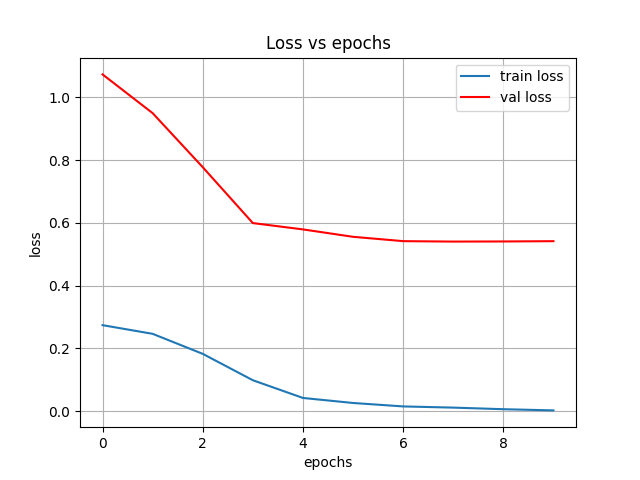
Metrics
So in general, loss vs ephocs need to go down, while in general accuracy goes up. I trained my model on 10 epochs, but it seems like 6 or 8 would have been enough.

Predictions
Which is usually the most exciting part. And yes it was!
import cv2
from PIL import Image
from ultralytics import YOLO
model = YOLO("./runs/classify/train9/weights/best.pt")
results = model.predict(source="./test/shark2-web.jpeg", show=False)
animals_dict = results[0].names
predictions = results[0].probs.tolist()
print(animals_dict)
print(predictions)
Testing with real data
For the following image (taken from internet), the model predicted SHARK! Which is correct! That is, in fact the signal for “shark!”

{0: 'bluespotted', 1: 'octopus', 2: 'shark'}
[8.831784361973405e-05, 0.00036882510175928473, 0.9995429515838623]
# Yey! A high score (0.99) in the 2: 'shark' dictionary
# Very low scores in the other dictionaries!
In the second test, the model predicted Octopus! Which is correct!

{0: 'bluespotted', 1: 'octopus', 2: 'shark'}
[0.027885375544428825, 0.9467946290969849, 0.025320017710328102]
Results / Comments
Feeding synthetic data to an AI model seems to me, like filling someone’s brain with theoretical knowledge. And we all know where that leads. Except, I look at this experiment from a different angle:
The AI model is most likely capable to understand that the synthetic data is some sort of a human person. Hence when it recognizes a real human doing a similar gesture, perhaps that’s enough for those virtual neurons to fire up. Which leads me to question, where is the boundary between synthetic and real data, and how that flexes an AI model. Along with this, there are so many “ifs” flying around, the most prominent of them being: What if synthetic data is enough for intended usage ?
This approach could potentially make training models for these sort of applications, .. cheaper ?
With, for example Unreal Engine / Unity engines reaching very good levels of photorealism, it would be actually sensible from a cost perspective, to recreate a digital reality and train AI models on it ?
That’s a thought!
To do
- Complete the synthetic dataset for all gestures
- Further testing / fine tuning
- Experiment with different models
- Work on my results presentations and perhaps more in-depth breakdowns.